반응형
2023년 2학기 전공 수업 중간고사 팀프로젝트로 진행하였던 코로나19 적정 병상 예측 모델 보고서와 코드입니다. 전처리 부분을 제외한 모든 부분은 제가 작성했고, 보고서는 완전히 개인 과제니까 안심하고 보셔도 됩니다. 제 학교랑 전공은 사실 티스토리에 오픈한지 꽤 되어서 가려봐야 의미가 없을 것 같으니 그냥 두고 이름이랑 학번만 가렸습니다.
보고서


혹시 궁금하신 분 있을까봐... 코드 그래도 혹시 몰라서 제가 작성한 부분이 아닌 코드는 삭제했습니다.
import pandas as pd
df = pd.read_csv('/content/xy_data_raw.csv')
df.head()
#numpy_array 형태로 변환
death = (df['mortality']).to_numpy()
features = (df.iloc[:,1:8]).to_numpy()
#train set, test set 분할
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(features, death, random_state=42)
print(train_input.shape)
print(test_input.shape)
#정규화(standard scaler)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(train_input)
train_scaled = scaler.transform(train_input)
test_scaled = scaler.transform(test_input)
#Model selection
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(train_scaled, train_target)
print(lr.score(test_scaled, test_target))
#사이킷런 변환기
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(include_bias = False)
poly.fit(train_scaled)
train_poly = poly.transform(train_scaled)
#print(train_poly.shape)
train_poly = poly.transform(train_scaled)
test_poly = poly.transform(test_scaled)
#다중회귀모델 훈련
lr = LinearRegression()
poly = PolynomialFeatures(degree = 10, include_bias = False)
poly.fit(train_scaled)
lr.fit(train_poly, train_target)
print(lr.score(train_poly, train_target))
print(lr.score(test_poly, test_target))
#1.0
#-0.30430900648567105
#훈련 세트는 1, 테스트 세트는 극히 작은 수 - 교재와 같은 상황 발생
#따라서 규제를 추가한다.
#Ridge regularization
from sklearn.linear_model import Ridge
ridge = Ridge()
ridge.fit(train_scaled, train_target)
print(ridge.score(train_scaled, train_target))
print(ridge.score(test_scaled, test_target))
#0.9888860272733656
#0.9772522995224812
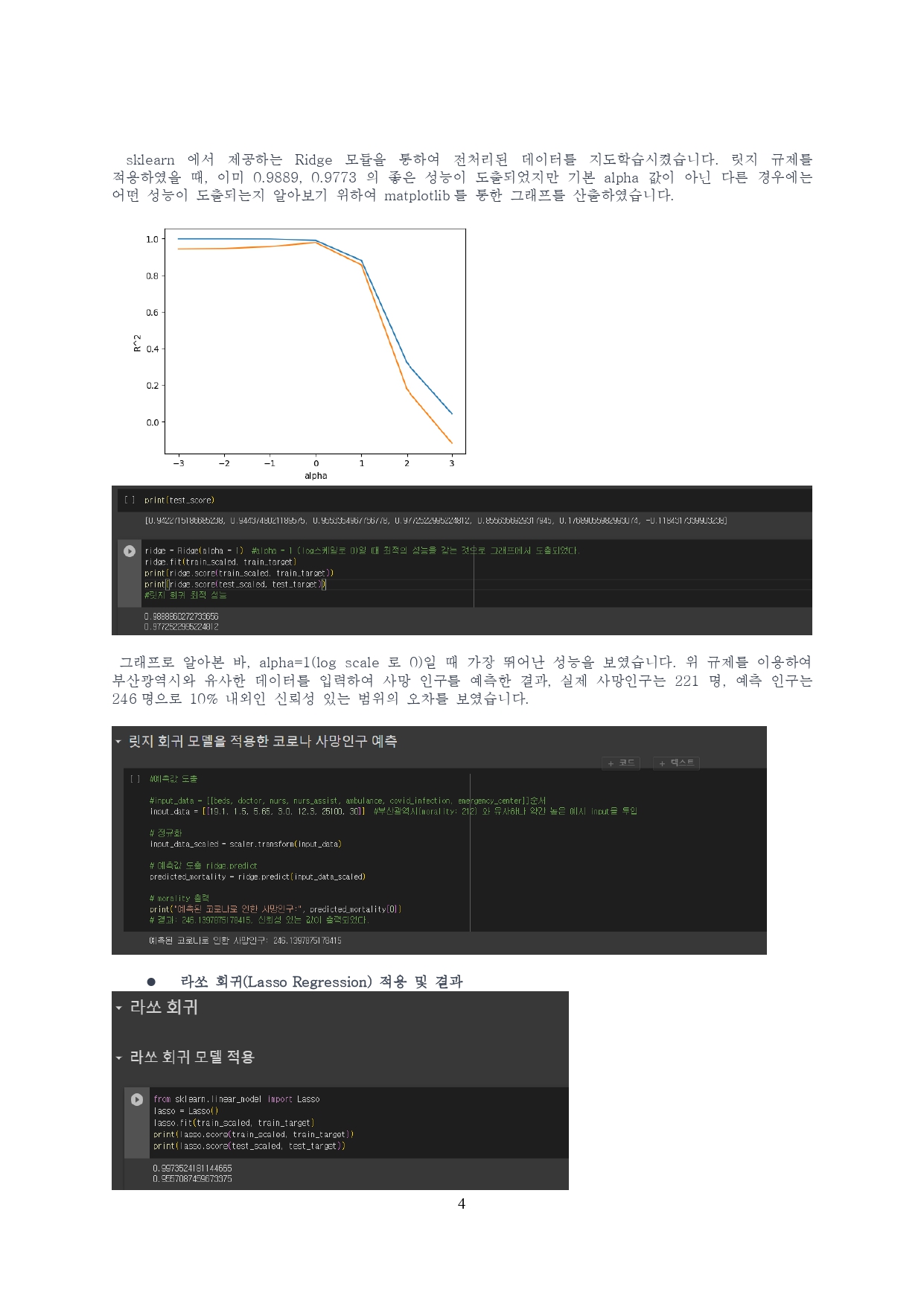
#이미 좋은 score가 도출되었지만, 최선의 성능을 찾기 위해 가장 적합한 alpha 값을 알아본다
import matplotlib.pyplot as plt
train_score = []
test_score = []
alpha_list = [0.001,0.01,0.1,1,10,100,1000]
for alpha in alpha_list:
ridge = Ridge(alpha = alpha)
ridge.fit(train_scaled, train_target)
train_score.append(ridge.score(train_scaled, train_target))
test_score.append(ridge.score(test_scaled, test_target))
import numpy as np
plt.plot(np.log10(alpha_list), train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.xlabel('alpha')
plt.ylabel('R^2')
plt.show()
print(test_score)
#[0.9422715186685238, 0.9443748021189575, 0.9553354967756778, 0.9772522995224812, 0.8556356929317945, 0.17689055982993074, -0.1184317339903238]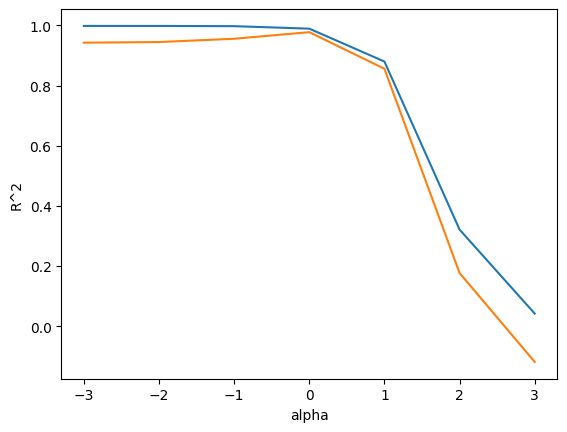
ridge = Ridge(alpha = 1) #alpha = 1 (log스케일로 0)일 때 최적의 성능을 갖는 것으로 그래프에서 도출되었다.
ridge.fit(train_scaled, train_target)
print(ridge.score(train_scaled, train_target))
print(ridge.score(test_scaled, test_target))
#릿지 회귀 최적 성능
#0.9888860272733656
#0.9772522995224812
#디폴트로 설정된 알파(1)이 가장 높은 성능을 나타냈다.
#예측값 도출
#input_data = [[beds, doctor, nurs, nurs_assist, ambulance, covid_infection, emergency_center]]순서
input_data = [[19.1, 1.5, 5.65, 3.0, 12.3, 25100, 30]] #부산광역시(morality: 212) 와 유사하나 약간 높은 예시 input을 투입
# 정규화
input_data_scaled = scaler.transform(input_data)
# 예측값 도출 ridge.predict
predicted_mortality = ridge.predict(input_data_scaled)
# morality 출력
print("예측된 코로나로 인한 사망인구:", predicted_mortality[0])
# 결과: 246.1397875178415, 신뢰성 있는 값이 출력되었다.#Lasso Regularization
from sklearn.linear_model import Lasso
lasso = Lasso()
lasso.fit(train_scaled, train_target)
print(lasso.score(train_scaled, train_target))
print(lasso.score(test_scaled, test_target))
#0.9973524181144665
#0.9557087459673375
#alpha 확인
train_score = []
test_score = []
alpha_list = [0.001,0.01,0.1,1,10,100,1000]
for alpha in alpha_list:
lasso = Lasso(alpha = alpha)
lasso.fit(train_scaled, train_target)
train_score.append(lasso.score(train_scaled, train_target))
test_score.append(lasso.score(test_scaled, test_target))
import numpy as np
plt.plot(np.log10(alpha_list), train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.xlabel('alpha')
plt.ylabel('R^2')
plt.show()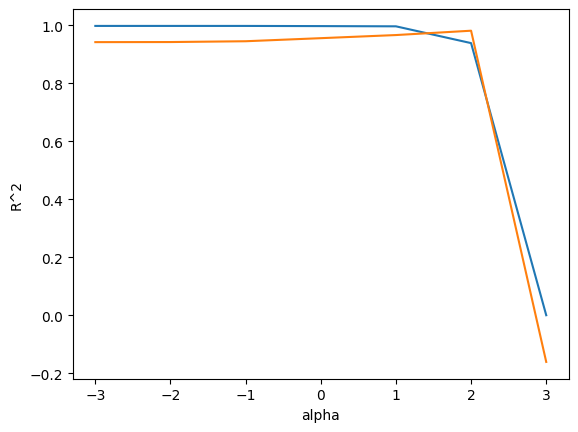
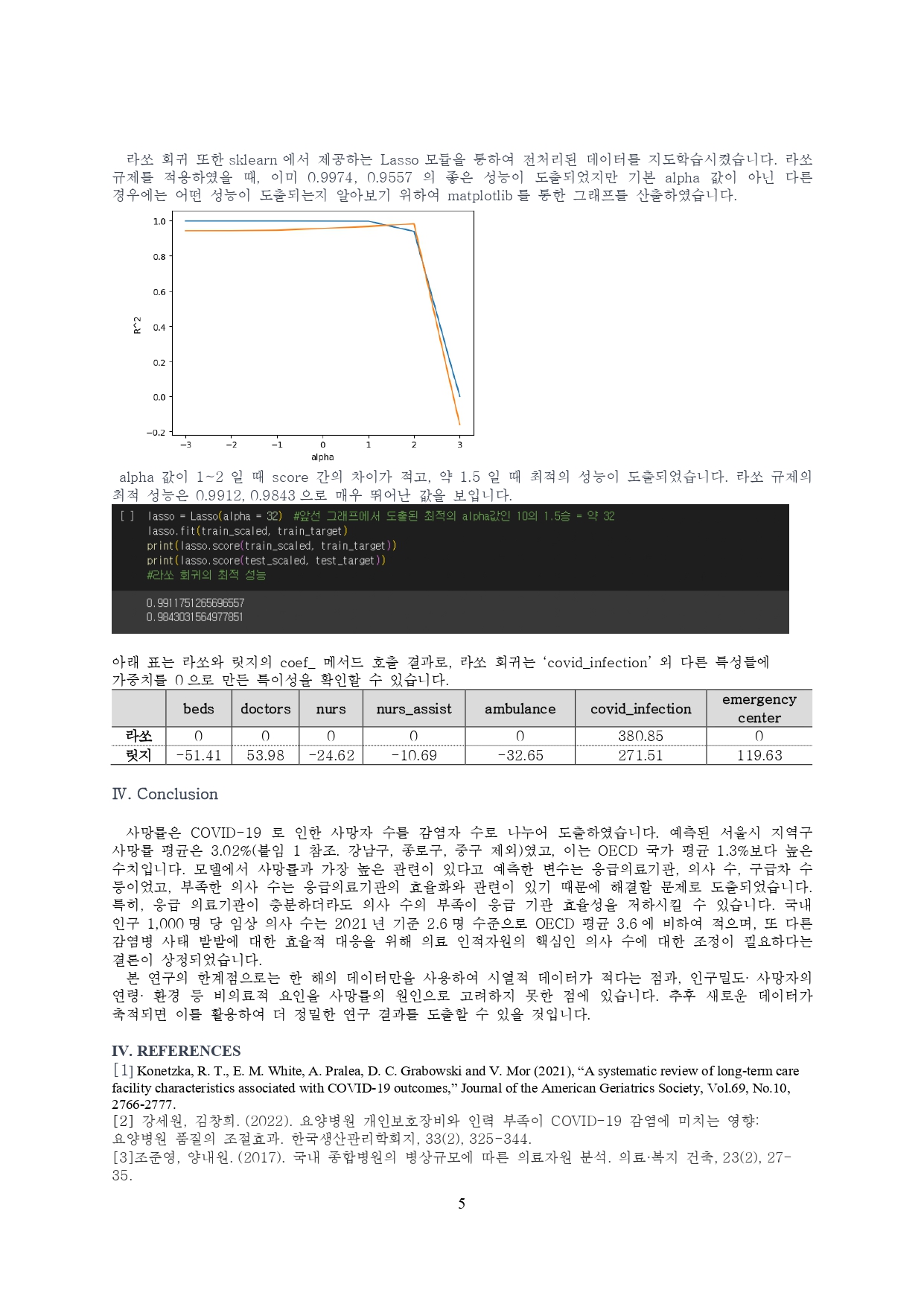
#alpha 값이 1~2일 때 가장 train score와 test scrore 간의 차이가 적고, alpha = 100^2 이후에는 급격히 두 score모두가 낮아진다.
#두 규제를 모두 적용한 결과, Linear Regression과 규제 추가 전 다중회귀 모델보다 성능이 상승되었다.
lasso = Lasso(alpha = 32) #앞선 그래프에서 도출된 최적의 alpha값인 10의 1.5승 = 약 32
lasso.fit(train_scaled, train_target)
print(lasso.score(train_scaled, train_target))
print(lasso.score(test_scaled, test_target))
#라쏘 회귀의 최적 성능
#0.9911751265696557
#0.9843031564977851
#input_data = [[beds, doctor, nurs, nurs_assist, ambulance, covid_infection, emergency_center]]순서
input_data = [[19.1, 1.5, 5.65, 3.0, 12.3, 25100, 30]] #부산광역시(morality: 212) 와 유사하나 약간 높은 예시 input 투입
# 정규화
input_data_scaled = scaler.transform(input_data)
# 예측값 도출 lasso.predict
predicted_mortality = lasso.predict(input_data_scaled)
# morality 출력
print("예측된 코로나로 인한 사망인구:", predicted_mortality[0])
#결과: 212.7227876480062로 신뢰성이 높다.
#참고: 릿지 회귀 결과는 246.1397875178415 였다.#Ridge, Lasso coef 확인
lasso.coef_
#array([ -0. , 0. , -0. , -0. ,
-0. , 380.85176057, 0. ])
ridge.coef_
#array([-51.41174524, 53.98269999, -24.61810674, -10.68883542,
-32.64575157, 271.50915199, 119.62739117])
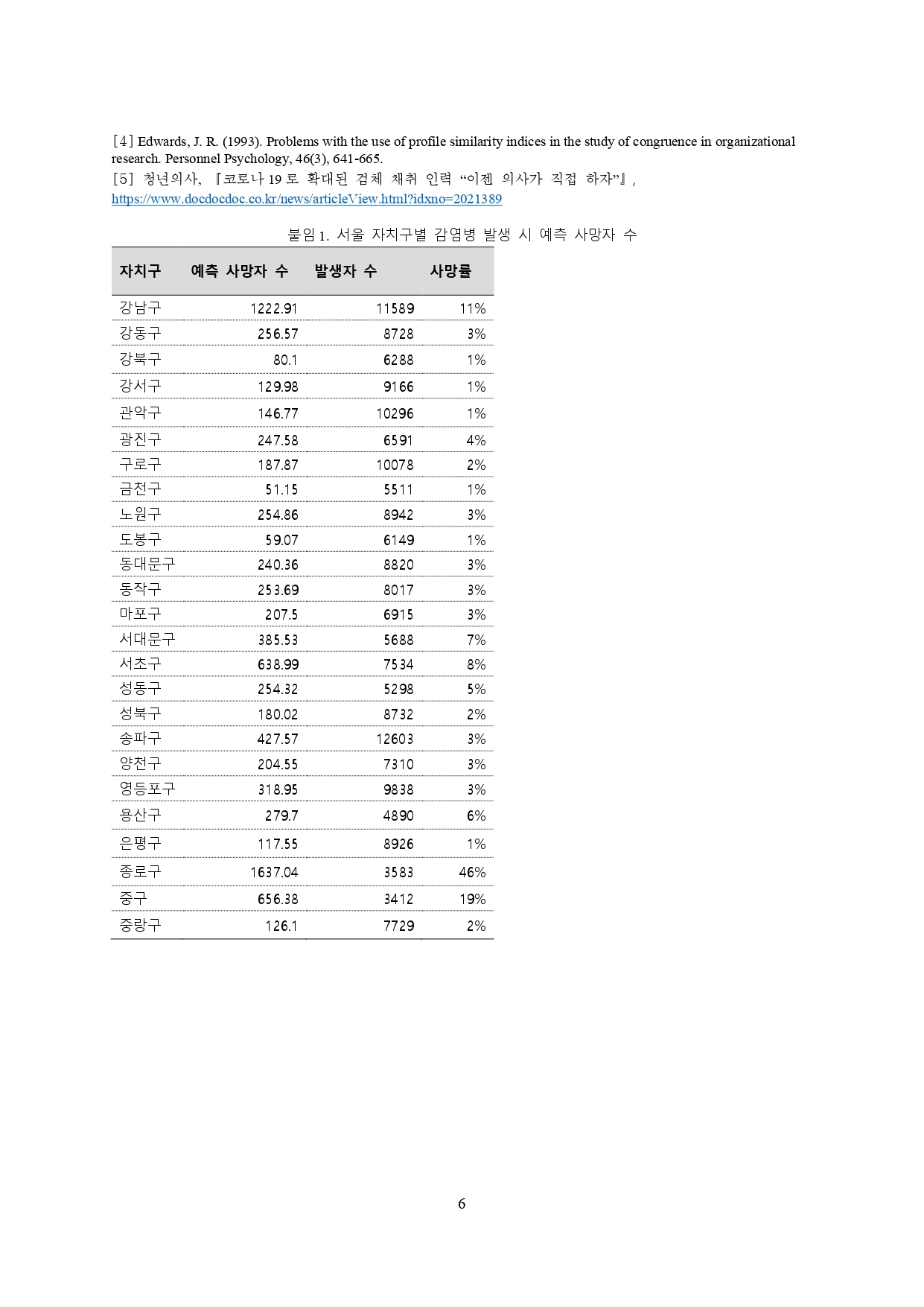
#직접 데이터를 투입하여 코로나 사망 인구를 예측해보기
#test1
#사용자에게 데이터를 입력받아 이중리스트로 변환
usr_input = input("(인구 천 명당) 침상 수, 의사, 간호사, 간호조무사, 구급차, 발생인구를 입력해주세요(예시: 19.1, 1.5, 5.65, 3.0, 12.3, 25100, 30): ") #콤마로 구분
input_lst = usr_input.split(",")
input_lst = [[float(x) for x in input_lst]]
print(input_lst)
# 정규화
input_data_scaled = scaler.transform(input_lst)
# 예측값 도출 ridge.predict
ridge_predicted_mortality = ridge.predict(input_data_scaled)
# 예측값 도출 lasso.predict
lasso_predicted_mortality = lasso.predict(input_data_scaled)
# morality 출력
print("릿지 회귀모형으로 예측된 코로나로 인한 사망인구:", ridge_predicted_mortality[0])
print("라쏘 회귀모형으로 예측된 코로나로 인한 사망인구:", lasso_predicted_mortality[0])
#(인구 천 명당) 침상 수, 의사, 간호사, 간호조무사, 구급차, 발생인구를 입력해주세요(예시: 19.1, 1.5, 5.65, 3.0, 12.3, 25100, 30): 19.1, 1.5, 5.65, 3.0, 12.3, 25100, 30
[[19.1, 1.5, 5.65, 3.0, 12.3, 25100.0, 30.0]]
#릿지 회귀모형으로 예측된 코로나로 인한 사망인구: 246.1397875178415
#라쏘 회귀모형으로 예측된 코로나로 인한 사망인구: 212.7227876480062
#test2
usr_input = input("(인구 천 명당) 침상 수, 의사, 간호사, 간호조무사, 구급차, 발생인구를 입력해주세요(예시: 19.1, 1.5, 5.65, 3.0, 12.3, 25100, 30): ") #콤마로 구분
input_lst = usr_input.split(",")
input_lst = [[float(x) for x in input_lst]]
print(input_lst)
# 정규화
input_data_scaled = scaler.transform(input_lst)
# 예측값 도출 ridge.predict
ridge_predicted_mortality = ridge.predict(input_data_scaled)
# 예측값 도출 lasso.predict
lasso_predicted_mortality = lasso.predict(input_data_scaled)
# morality 출력
print("릿지 회귀모형으로 예측된 코로나로 인한 사망인구:", ridge_predicted_mortality[0])
print("라쏘 회귀모형으로 예측된 코로나로 인한 사망인구:", lasso_predicted_mortality[0])
#(인구 천 명당) 침상 수, 의사, 간호사, 간호조무사, 구급차, 발생인구를 입력해주세요(예시: 19.1, 1.5, 5.65, 3.0, 12.3, 25100): 14.2, 1.5, 6.78, 2.0, 10.4, 20000.0, 15
[[14.2, 1.5, 6.78, 2.0, 10.4, 20000.0, 15.0]]
#릿지 회귀모형으로 예측된 코로나로 인한 사망인구: 150.37294713434437
#라쏘 회귀모형으로 예측된 코로나로 인한 사망인구: 169.8012907472546반응형
'프로젝트 끄적끄적 > 학교 프로젝트' 카테고리의 다른 글
| 차세대시스템설계론 최종과제 - 로그인 기능이 있는 논문 검색 웹사이트 (0) | 2025.01.15 |
|---|---|
| [Python논문쓰기] 한국 방문 외국인 유학생 통계를 중심으로 한 한국 대학의 유학생 정책 개선 연구 (0) | 2024.09.09 |
| NLP 기반 야구경기 기록과 선수 네트워크 분석 - 최종보고서 (0) | 2023.12.18 |
| NLP 기반 야구경기 기록과 선수 네트워크 분석 - 소개ppt (0) | 2023.12.18 |



